Computer Science has provided a very useful lens through which to study living things. Developing software often requires designing a way to take in information, process that data, and then make decisions on a course of action. There are many routes to go about doing this, from hard coding all possible inputs and responses to each to far more complicated and nuanced implementations that try to deal with or mimic the fuzzy and messy complexity of the real world.
Living things- from single celled organisms to blue whales- are the same. They operate under the same paradigm. Information from the environment (predator and safety location, location of food or of poisons, physical dangers, group dynamics, etc) is taken in and, based on its survival strategy, it will respond to that environment. In computer science terms, we would call this information processing.
Studying how living organisms perform these functions without the obvious use of recognizable switches, decoders and logic units, of blocks of program code or anything else we associate with the devices we create is a fascinating subject.
Instead of a Software world living things exist in a Wetware world, processing information and making decisions through the dance of atoms and molecules in DNA and proteins, in organelles and somatic systems, all to the music of the physical laws of chemistry. And it clearly works! After all, you are reading this (and I am writing it) with a brain inside a body.
So how do biological organisms process information (in the computer science sense) without the wires and silicon?

Let’s look at the bacteria E. Coli. We tend to have negative view of this organism due to its role in contaminating food. But it is an amazing little creature. Here’s a picture of it.
Notice the little tails coming off it on the right? They are rotating together in one direction. If we zoom in on where that tail connects to bacteria, we can see its resemblance to a motor.
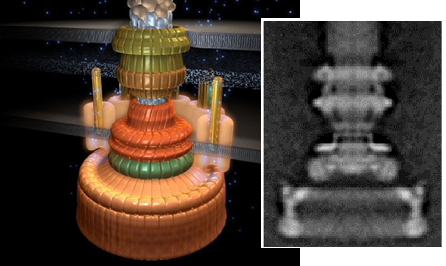
This “outboard” motor spins at up to 17,000 rpms counterclockwise. It runs on a hydrogen ion imbalance engine. Outside the bacteria there a lot of hydrogen ions, while inside there are few, creating what is called a gradient. Like water flowing in a river to turn a waterwheel, the hydrogen ions flow into the engine and in the process turn it. It’s a little more complicated than that, as the flow of protons don’t actually turn the tails physically in the same way water pushes a wheel, but the principle is the same. There is a pressure differential that results in kinetic movement of the tails just as there is in the wheel.
In the front of the E. Coli bacteria are several receptors, or sensors ((the brown points at the left) that detect things like food (attractants) and dangerous chemicals (repellents). The motors spin the tails, moving the bacteria along like a ship. The sensors constantly sample the environment around it. If it detects the amount of food is increasing in the direction it is going, it continues towards it.
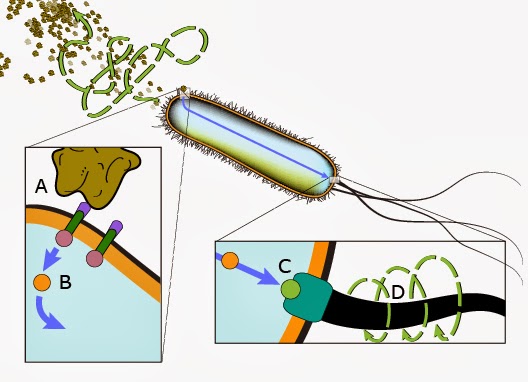
But if the amount of food doesn’t increase, goes down, or even more dangerous, contains harmful substances, all the motors reverse direction and each tail independently spins clockwise, causing the bacteria to spin about chaotically so that it is pointing in a new random direction. This is called tumbling. Then the engines reverse direction and the tails sync up into a single tail again, propelling the bacteria straight forward in that new direction, once again sampling the new environment and starting the information processing all over again.
The fact that it can tell if it is moving toward or away from food means it is exhibiting a kind of memory, since it needs to compare the current food concentration from a moment ago to that of now. The same is true regarding the concentration of repellents. The ability to analyze all the information coming from the sensors and from its memory in order to decide whether to change course speaks of the existence of some kind of information processing apparatus.
How is this little single celled organism doing all that? Humans or dogs have brains, organs and tissue and a nervous system that seems to do this. Not so, E. Coli. What is its memory? How does it synthesize that information and then make decisions to control its movement? What are the processing components involved?

To better understand what we are looking for, we can ask how this is done in computers. At its basic level, the heart of a computer is literally a switch, a simple circuit that can be turned on or off. That’s it. Seriously, I’m not joking. (To get a feel for this, see my post “Building a computer from scratch”.) These switches are connected (in ascending and expanding layers of complexity) until ultimately, we create a CPU, the Central Processing Unit, to read data (take in information), perform simple computations based on that data to get a result, and then make decisions on a course of action based on that. It is incredibly complex, but the rudimentary component is the switch.
So what then is the equivalent of a “switch” in living systems?
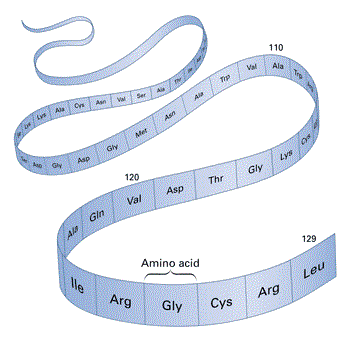
The answer to that is protein. A protein is a chain of molecules called amino acids. These acids (there are only 20 of them used in living things) are like letters of an alphabet. Just as you combine (or chain) letters together in infinite (but meaningful) combinations called words and sentences, amino acids are chained together in a long train. Each amino acid has its own magnetic “stickiness” of varying strength. Imagine you have a rope made of segmented pieces each with some sort of sticky material on it. And imagine that some segment’s “stickiness” may be weak- just tacky to the touch. Others may be stronger, like duct-tape or even crazy glue. And still others are in between. Now also imagine that certain segments stick tightly only to other certain segments and they may only stick weakly or not at all to others.
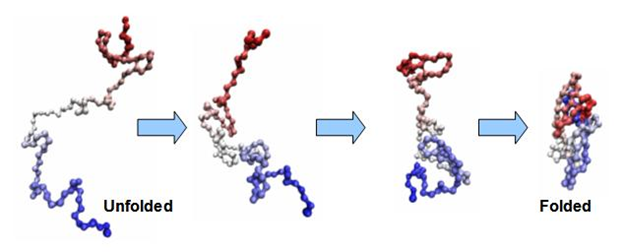
You could now take this rope fold it into itself so that different segments bind to other segments. When you let the rope go, it keeps the newly folded shape. This is what happens with a chain of amino acids. After a chain of amino acids is created, it is then folded together into a protein with a very specific shape. This shape gives it both stability and, much more importantly, functionality. Its function follows its form.
Proteins can be long or short and can fold into a near infinite number of shapes. They can also be fitted together to form even larger structures, can bond with other proteins and molecules, and can even move. This type of functional flexibility makes them the main workhorse of all living things.
Ok. so we have proteins. Do cells assemble switches and circuits in the same way engineers do to create computer circuits? No. They use a different method.
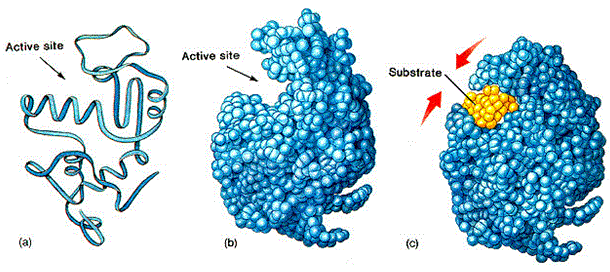
Let’s go back to our original newly folded protein made up of a chain of amino acids. There are all kinds of nooks and crannies in this protein chain. These spots (called active sites) are specifically shaped so that not just any molecule or protein can fit inside it. Only specific kinds of can fit, like a key in a lock. The fit is not just based on the shape but the “stickiness” of the segments in those active sites. When a specific protein or other molecule with the correct shape and charge comes along and fits, it physically and magnetically binds into that site.
When something is bound to that activation site, it subtly affects the electromagnetic makeup of the various segments of the protein. In response, the protein may change its shape or may do something else. Both proteins and molecules can bind to these active sites and cause these kinds of changes. A protein that causes a change like this is called an enzyme.
It is this binding, changing shape and thus modification of function (remember, function follows form) that is at the heart of the taking in information from the environment and processing that data, things we normally associate with software.
So with that in mind, let’s dive deeper and get the details.
In the very front of the bacteria, embedded in its cell wall, are several receptors made up of groups of proteins that have been fitted together. These structures extend so that part of them jut out into the environment it is swimming in while the rest remains safely ensconced inside. The part of the protein that is outside contains the “locks” or active sites that will bind to certain types of substances, some attractants like food, and some repellants like poisons. There is a whole array of these sensors in the front of the cell, all sampling the environment. When one of these meets something that fits that lock, food for example, then it binds with it. That binding causes a cascade of shape changes that propagate through the sensor until what is inside the cell has also changed shape.
Now the sensors could just “wire up” directly with the motors. While this direct connection may sound like a good idea, it is not the best strategy. Rather than just be content with whatever amount of food, however low, is available, E. Coli should always be seeking richer sources. This maximizes the chances of it getting enough. Conversely, if it detects a dangerous substance it needs to make sure when it does change direction, it is not in the direction where the danger is increasing. This is a strategy optimized for survival
An indirect connection, one that utilizes memory for comparison with previous conditions, is the key. This gives the bacteria the ability to process all the sensory data (the changing concentration of all repellents and attractants) together first before it can intelligently (at least for a bacteria) decide whether to keep going or change direction.
All of this is done with 3 stages of processing.
1) Chemoreception: An attractant or repellent binds to the sensor proteins. As I mentioned, this causes a subtle shape change that cascades through the sensor’s body, including that which is inside the cell.
2) Signaling: At that end of those sensors is a unit that controls the changing states of a particular enzyme, CheY. This enzyme is what is called “self-catalyzing”, in that it constantly switches between one shape, called the active one, and another, called inactive. The end unit on this sensor switches active CheY back to inactive. The CheY automatically switches back to active on its own. The sensor deactivates CheY. And so on. Active and inactive, over and over again.
When CheY is active, it binds to the tail motors, specifically the mechanism that controls the direction of their spinning. Think of it like lint clogging a filter. When there is more active CheY binding to the motors, there is a higher chance that they will flip and change direction from counterclockwise to clockwise. This suddenly clockwise spinning of all the tails will cause the bacteria to tumble about pointing in various directions. When the motor eventually reverts back to counterclockwise (through another reaction), the tails once again sync up so that now the bacteria is traveling in a new direction.
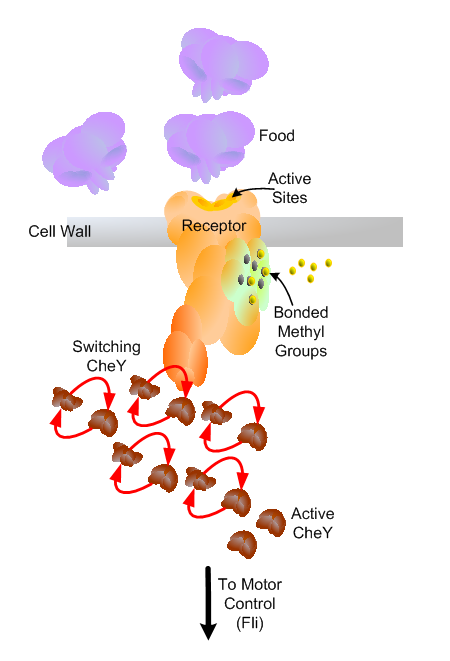
3) Adaptation: When the sensors can keep up to deactivate the constantly activating CheY, they don’t have an opportunity to build up in the motor. But if the sensor slows down its deactivation of CheY, it can’t keep up. Active CheY builds up and begins to affect the motor and the chance of tumbling gets higher.
So then, what affects the rate of the sensor’s control of active CheY? Another subunit of the sensor contains active sites for methyl groups (a certain family of organic molecules) to bind to. The strength and rate of that binding can change. If it goes up, more methyl is bonded. If it goes down, less methyl is bonded.
What the sensor is exposed to affects that methyl bonding. When the sensor is exposed to an attractant, more methyl groups are bonded and kept. When it is exposed to a repellent, methyl groups are released and new binding is slower, resulting in less methyl groups in the sensor. This means that the concentration of methyl groups reflects the state of the environment in the immediate past! It is a memory of past conditions.
So we have two sources of information to each sensor.
1) The live current state of the environment at that moment, based on whether it is currently bonded to an attractant (food) or repellent.
2) The “memory” of the environment in the immediate past- the methyl group concentration.
Here is where the magic occurs!
The sensor unit then responds to the combination of chemical changes from both sources of input, from both data sources, and it experiences a conformational change. This shape change is in fact a computation, a operation based on inputs to yield a new, consistant output.
In mathematical terms, this is a function that takes in two pieces of data and returns the result of the comparison between the two.
If the concentration of food has gone up, then the subunit that is controlling the deactivating of CheY keeps up, which means they don’t bind in the tail motors, decreasing increasing the likelihood of a directional change (in other words, away from all that sweet sweet food!) Instead, it (happily?) continues on eating to its figurative heart’s content.
Conversely, when the concentration of repellents has gone up, the switch control subunit slows down and active CheY builds up. The likelihood of a directional change increases, resulting in a tumble in a new, hopefully safer direction. If the direction is still bad, it will tumble again (and again…), repeating until it is moving on to safety.
Thousands of sensors all working independently, processing their data, and contributing their results to the control of the motors. The net result is that the bacteria can go where it has the best chance to survive, eat, and reproduce.
Brilliant! An entire information processing system built from proteins and the behaviors that derive from the chemical laws that govern them. This is an analog computer, albeit one built of biological components, dealing with real world rather than digitally encoded information, processing through physical laws and interactions rather than by programmed algorithms.
Wetware.
There are other wetware systems that are more like those we have designed. And conversely, our study of wetware systems such as neural networks, distributed processing and principles of emergence has resulted in the explosion of machine learning. From apps that tell us we may need to buy milk, or suggest a song we might like, or recognize a voice, the principles we have learned from wetware systems have revolutionized computer science.
But more fundamentally, it has also helped us to see that deep down, it is ALL information. Life AS information. Life IS information. The principles of Information Theory run deeper than our modern world. It is the new paradigm through which we might finally understand the mysteries of life.
Here are some links to some amazing books and videos on the subject of Wetware, organic computing, Life as information, and more.





